URL:
https://linuxfr.org/news/sortie-de-uchardet-0-0-8-pour-la-detection-de-codages-de-caracteres
Title: Sortie de uchardet 0.0.8 pour la détection de codages de caractères
Authors: Jehan
Julien Jorge et Benoît Sibaud
Date: 2022-12-19T22:40:57+01:00
License: CC By-SA
Tags: langues, codage, librairie et bibliothèque
Score: 5
[`uchardet`](
https://www.freedesktop.org/wiki/Software/uchardet/) est une bibliothèque C/C++ de détection de [codage de caractère](
https://fr.wikipedia.org/wiki/Codage_des_caract%C3%A8res) (par exemple `UTF-8` ou `ISO-8859-15` sont ce qu’on appelle des « codages de caractères » ou « jeux de caractères ») basée sur des caractéristiques statistiques des langages naturels et membre du projet *Freedesktop*. Elle peut détecter quelques dizaines de codages de caractères.
Le projet fournit également un outil en ligne de commande pour tester très simplement le codage de vos fichiers ou de flux de texte.
`uchardet` version 0.0.8 est sortie ce 8 décembre 2022.
----
[Site d'uchardet](
https://www.freedesktop.org/wiki/Software/uchardet/)
[Dépôt de code](
https://gitlab.freedesktop.org/uchardet/uchardet/)
[Financement de développement par projet ZeMarmot](
https://liberapay.com/ZeMarmot/)
----
# Usage
## Outil en ligne de commande
L’outil en ligne de commande n’est nullement le point principal du projet, mais reste fort utile si vous avez un fichier texte dont vous n’êtes pas sûr du codage:
```sh
$ uchardet mon-fichier.txt
ISO-8859-15
```
Si vous inspectez plusieurs fichiers à la fois, la sortie contiendra une ligne par fichier, préfixée du nom de fichier:
```sh
$ uchardet test/fr/iso-8859-15.txt test/de/windows-1252.txt
test/fr/iso-8859-15.txt: ISO-8859-15
test/de/windows-1252.txt: WINDOWS-1252
```
Accessoirement vous pouvez l’utiliser en mode `pipe` pour récupérer un flux de données. Pour prendre un exemple réaliste, regardons la [page web archivée](
https://www-archive.mozilla.org/projects/intl/universalcharsetdetection) qui explique l’algorithme à l’origine de cet outil (j’en parle dans [l’historique](#toc-2002-2011-code-universalchardet-chez-mozilla)). Très ironiquement, cette page s’affiche avec des caractères de remplacement '�' dans Firefox, ce qui indique une erreur de décodage (pour qui n’a pas compris en quoi c’est ironique : ce projet était originellement fait par Mozilla pour Firefox, mais il n’est plus inclus depuis de nombreuses années et maintenant même la page en parlant est mal affichée).
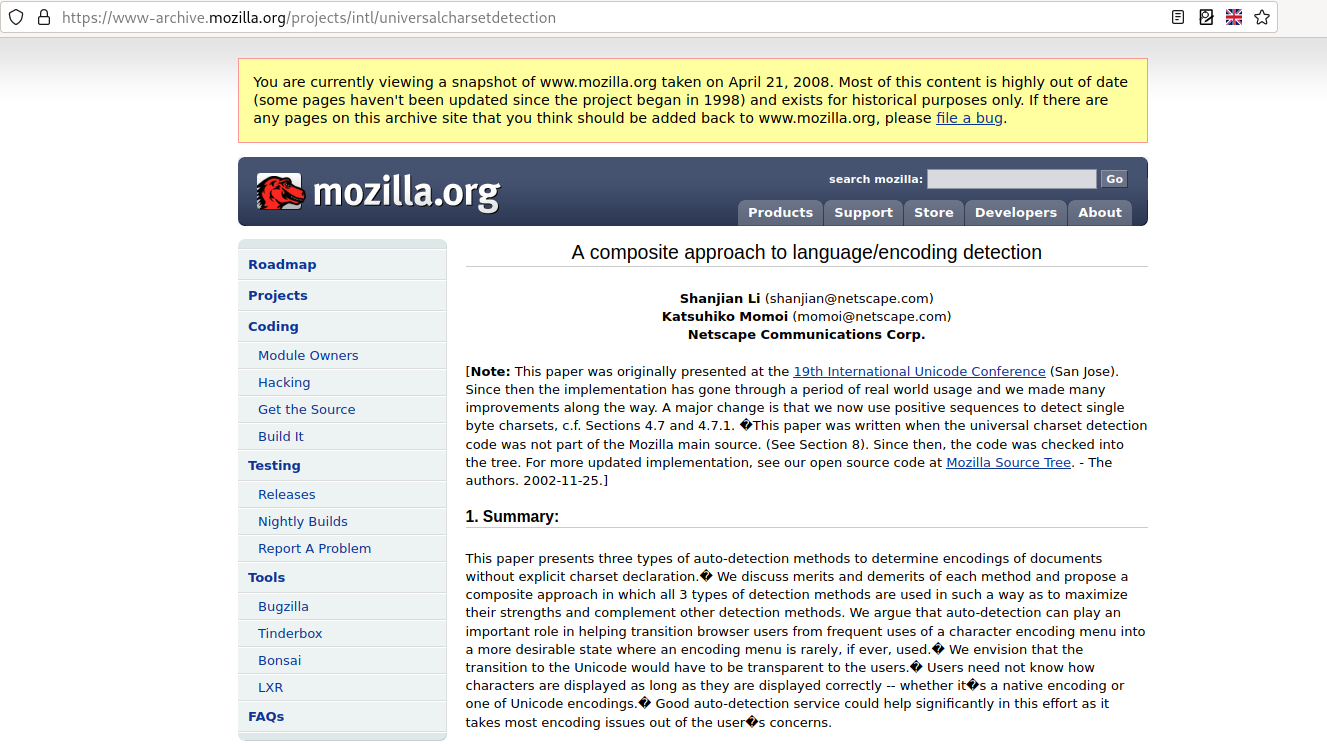
La raison est que le serveur web lui-même envoie un en-tête `content-type: text/html; charset=UTF-8`, même si la page web contient bien un `charset=windows-1252` en métadonnées. Firefox semble privilégier l’en-tête envoyé par le serveur.
Supposons néanmoins que nous n’ayons aucune métadonnée (ni côté serveur, ni dans le code HTML) et que nous voulions deviner le jeu de caractères:
```sh
$ curl
https://www-archive.mozilla.org/projects/intl/universalcharsetdetection | uchardet
WINDOWS-1252
```
Et voilà! Notons qu’idéalement, vous devriez même retirer tout texte structurel qui pourrait interférer avec la détection (j’en reparlerai dans la section sur les [principes](#toc-conclusion-2-uchardet-ne-fait-pas-de-magie-mais-nen-est-pas-moins-impressionnant) de détection. Par exemple pour retirer les tags HTML sur une seule ligne:
```
$ curl
https://www-archive.mozilla.org/projects/intl/universalcharsetdetection | sed 's/<[^>]*>//g' | uchardet
WINDOWS-1252
```
Cela peut sembler inutile ici puisque l’outil a eu bon dès le début, mais ne pas en prendre l’habitude peut aisément créer des faux positifs.
*Note: il s’agit d’un « nettoyage » simpliste d’un source HTML, pour démonstration. Notamment avec les nouvelles API de détection de langage (voir la section « [Futur: API de détection de langage](#toc-futur-api-de-détection-de-langage) »), j’obtiens parfois des erreurs de détection de langage si je prends une page Wikipédia sans bien la nettoyer, car il y a beaucoup de contenu structurel dans le code des pages Wikipedia.*
Notons que les noms de codage sont compatibles avec `iconv`. Par conséquent vous pouvez très aisément utiliser le résultat directement pour convertir dans un codage qui vous convient mieux, si nécessaire. Par exemple, maintenant que vous savez que le texte est en `WINDOWS-1252`, transformons le en `UTF-8`:
```sh
$ curl
https://www-archive.mozilla.org/projects/intl/universalcharsetdetection | iconv -f WINDOWS-1252 -t UTF-8
```
## Interface de programmation
L’API d’`uchardet` est en C/C++ (implémentation en C++ mais interfacée pour être aisément incluse dans du code C ou C++) et [extrêmement simple](
https://gitlab.freedesktop.org/uchardet/uchardet/-/blob/v0.0.8/src/uchardet.h#L58-105) : vous créez un objet `uchardet_t`, vous l’alimentez en données textuelles (en une fois ou par lots), puis vous obtenez le codage de caractère au format texte, compatible avec `iconv`:
```C
#include <uchardet.h>
const char *
print_charset(const char* data,
size_t data_len)
{
const char *charset
uchardet_t handle;
handle = uchardet_new();
uchardet_handle_data(handle, data, data_len);
uchardet_data_end(handle);
charset = uchardet_get_charset(handle);
printf("%s\n », charset);
uchardet_delete(handle);
}
```
Notons que l’un des grands avantages d’`uchardet` est sa rapidité exemplaire. C’est un système basé sur des modèles statistiques de langage, générés sous forme de code C++, puis compilés, qui est capable de déterminer le codage d’un fichier très rapidement, car basé sur des logiques très simples mathématiquement.
# Un peu d’histoire
Comme `uchardet` est très lié à ma propre expérience où je voulais originellement simplement satisfaire un besoin personnel, et que je me suis retrouvé à [maintenir des années une bibliothèque](
https://xkcd.com/2347/), je me suis dit que c’est une petite histoire marrante à raconter.
## 2002-2011: code `universalchardet` chez Mozilla
Le projet est né de Mozilla, il y a une vingtaine d’années (en tous cas, le papier est daté de 2002), sous le nom de `universalchardet`. Il me semble que le code fut même dans leur navigateur pendant plusieurs années.
Malheureusement je ne retrouve plus d’archive du code de l’époque (on trouve en fait la [structure du code archivé par le projet archive.org](
https://web.archive.org/web/20150730144356/http://lxr.mozilla.org/seamonkey/source/extensions/universalchardet/) mais le contenu des fichiers source n’est pas archivé). Seul le papier de recherche qui explique les bases des algorithmes utilisés est encore [disponible](
https://www-archive.mozilla.org/projects/intl/universalcharsetdetection).
## 2011-2015: intégration dans une bibliothèque dédiée
Néanmoins si quelqu’un est intéressé par le code d’origine, le [premier commit de `uchardet` en 2011](
https://gitlab.freedesktop.org/uchardet/uchardet/-/tree/3601900164aefb329a0493bd6448682c807fa6cb) donne probablement un bon aperçu de ce à quoi ressemblait les dernières versions de Mozilla. À l’époque, le code était encore accessible sur les dépôts de Mozilla, mais il ne pouvait être aisément utilisé par d’autres projets, hormis en le copiant manuellement. BYVoid, le mainteneur originel de cette bibliothèque a donc extrait le code des dépôts Mozilla pour créer l’interface que j’ai [montrée plus haut](#toc-interface-de-programmation).
C’est ainsi que pendant quelques années, de 2011 à 2015, il y eut un peu de nettoyage et maintenance par BYVoid et quelques autres contributeurs. Pendant cette période, on compte un peu moins d’une trentaine de commits, et on peut considérer que ce fut principalement de la maintenance sans modification profonde du code originel.
## 2015: j’ai besoin de lire des sous-titres !
Les sous-titres de films furent mon entrée dans ce projet. Comme la plupart des occidentaux utilisant un alphabet avec des accents, j’avais déjà remarqué que les sous-titres de film étaient très souvent cassés. Quiconque a déjà vu ce genre de sous-titre sait de quoi je parle:
> Luke, je suis ton p�re!
Voire:
> Luke, je suis ton pÚre!
😅
Les jeunes générations ont peut-être moins ce problème, maintenant que `UTF-8` est vraiment mis en avant, mais il y a encore peu, beaucoup de textes en français étaient codés en `ISO-8859-1` ou `ISO-8859-15` (il peut aussi y avoir des textes français en `WINDOWS-1252` notamment).
Comme tout le monde avant moi, j’ai fait abstraction de ce problème pendant une décennie (puisque cela restait lisible avec de l’imagination). Sauf que le jour où j’ai donné des sous-titres en japonais ou coréen à `mplayer`, `mpv`, `VLC`, ou tout autre lecteur (j’ai vu ce problème même sous Windows, pour quiconque croirait que c’est juste sous Linux), on se retrouvait avec du texte absolument illisible (et ce quel que soit votre pouvoir d’imagination !). La solution était d’essayer tous les codages des listes proposées dans l’interface des lecteurs vidéos (des dizaines, car les gens sont rarement au courant des jeux de caractères habituels pour une langue, donc on les essaie tous). Même si à force, on peut mieux connaître les codages les plus “habituels” d’un langage cible, cela reste un processus frustrant et fastidieux.
Je regardai donc le code de `mpv` (fork de `mplayer`, excellent lecteur de vidéo) et vit qu’il utilisait `enca` pour détecter le codage des fichiers de sous-titre. Malheureusement son efficacité était très limitée (notamment le coréen et le japonais n’étaient pas pris en charge), et surtout sans donner un indice (*hint*) à `enca`, il est incapable de déterminer un codage mono-octet (c’est-à-dire notamment tous les `ISO-8859-*` et comme je disais, le français était souvent codé ainsi, ce qui expliquait les erreurs de décodage constantes). Cette très forte limitation s’expliquera très facilement quand vous lirez la section sur les principes de détection, plus bas.
Je me penchai alors sur l’état des lieux des bibliothèques de détection de codages de caractère. À l’époque, une autre bibliothèque libre ressortait dans toutes les recherches web : `libguess` (qui disait reconnaître plus de langues). Je la teste pour rapidement découvrir que le *hinting* est aussi obligatoire (ce que je confirme avec [le code](
https://github.com/kaniini/libguess/blob/b44a240c57ddce98f772ae7d9f2cf11a5972d8c2/src/libguess/guess.c#L58)). Et encore, en essayant un fichier `EUC-KR` (le codage le plus commun en Corée), avec "*korean*" en indice, la détection foirait. Ce n’est pas une validation très scientifique, mais comme les langues asiatiques étaient mes cibles principales (et européennes en secondaire), c’était mal parti.
C’est alors que je découvris `uchardet`. Il n’était pas parfait, mais clairement il marchait bien mieux (mes tests étaient très encourageants), et surtout ne nécessitait pas de rajouter des “indices” de langue pour être efficace.
En cette année 2015, je [poussai donc à son intégration dans `mpv`](
https://github.com/mpv-player/mpv/issues/908), puis je contribuai même un petit [patch](
https://github.com/mpv-player/mpv/pull/2193) additionnel pour en faire le détecteur par défaut (`enca` restait en second choix ; il est intéressant de noter que la prise en charge de ce dernier a été retirée totalement depuis).
Comme j’avais poussé à son usage, et que la maintenance de `uchardet` n’est pas au plus haut, je sentis le besoin de patcher des bugs. C’est ainsi que je fis mon premier patch dans `uchardet` cette même année.
*Aparté : c’est aussi un petit rappel pour ceux qui croient que l’informatique devrait être en ASCII seulement, et que c’est suffisant. La réalité est que nous ne sommes pas seuls sur terre, et pour avoir dû batailler pendant de nombreuses années avec nos systèmes libres pour simplement pouvoir lire du texte dans certaines autres langues (d’où mes contributions dans `uchardet`, `mpv` et d’autres projets), ou pour écrire dans ces langages (côté écriture, j’ai d’ailleurs contribué au moins un patch dans `ibus-hangul` ! Chaque usage cassé son patch ! 😩), je peux affirmer sans une once d’hésitation que nos systèmes libres ne sont pas si accueillants aux non-occidentaux. Cela s’améliore, mais c’est encore loin d’être parfait et sans pour autant dire aux développeurs bénévoles qu’ils devraient eux-mêmes implémenter des fonctionnalités dédiées, il faut être ouvert aux patchs qui améliorent l’internationalisation de votre logiciel (ce principe ne s’appliquant pas qu’aux textes affichés, mais aussi à l’interface et à la possibilité d’écrire du texte).
Il est important de reconnaître au moins que ces usages existent et qu’un logiciel (ou internet) n’est pas fait pour être ASCII seulement !*
## 2015-2022 : maintenance et (dé)cadence
Quoi qu’il en soit, c’est ainsi que je commençai à contribuer plus à `uchardet` puis en devint le co-mainteneur (puis rapidement le seul mainteneur puisque le projet était déjà en mode de maintenance minimale à l’époque).
J’ai immédiatement vu le potentiel du projet et c’est à ce moment-là que le projet a commencé à évoluer :
* Rendre les valeurs de retour `iconv`-compatible pour un interfaçage aisé (`iconv` étant le projet le plus commun pour de la conversion entre codages de caractères) dans des projets tiers.
* Ajouter des tests unitaires pour chaque combinaison de langage et de codage officiellement pris en charge et une infrastructure de tests automatiques pour éviter les régressions.
* Créer des scripts de génération de modèles de langage par extraction et traitement de données Wikipédia. C’était un changement majeur, car il permettait de facilement générer et regénérer des modèles pour détecter des langues et des codages.
* En conséquence du point précédent, de nombreuses prises en charge ont été très aisément ajoutées à `uchardet` qui reconnaît maintenant beaucoup plus de langues et de codages qu’à ses origines.
* Améliorer l’algorithme de “confiance” de détection, pour des résultats bien plus fiables qu’à l’origine.
* etc.
J’en fis aussi un projet [Freedesktop](
https://www.freedesktop.org/) assez rapidement puisque je compris qu’il y avait un réel manque dans le libre (les 2 autres alternatives ne marchant pas de manière satisfaisante) et que c’était donc un projet utile pour un bureau libre. En outre, c’était mieux ainsi, plutôt que sur le compte du précédent mainteneur (qui était d’accord pour ce changement bien sûr) sur une plateforme de gestion de source propriétaire (c’était en effet initialement publié sur un compte personnel sur *Github*).
# Comparaison avec d’autres projets en 2022
De nos jours, le « paysage logiciel » est un peu différent. D’un certain côté, ce type de détection est devenu bien moins nécessaire, car les formats ont souvent des métadonnées associées pour en indiquer le jeu de caractère. Sur le web par exemple, il est recommandé dorénavant de [déclarer ce dernier](
https://www.w3.org/International/questions/qa-html-encoding-declarations) alors que c’était plus chaotique, il y a une vingtaine d’années. Je n’ai pas d’information interne, mais j’ai toujours imaginé que c’était la raison pour laquelle Mozilla avait abandonné son propre code de détection (l’origine de `uchardet` donc). Je suppose qu’à un moment, ils se sont dit que ce n’était plus nécessaire lorsque les documents web sont devenus globalement bien “étiquetés”.
En outre, `UTF-8` a vraiment pris ses marques et est devenu lui-même de plus en plus le jeu recommandé dans une majorité d’usages, diminuant d’autant les chances de tomber sur d’autres codages de caractères sur des fichiers récents. D’ailleurs certains formats de fichiers ou protocoles récents ont fait le choix de rendre UTF-8 obligatoire (c’est le cas de XMPP dès les premières *RFC* par exemple).
Néanmoins les vieux fichiers (archives, etc.) existent encore, les gens s’échangent encore parfois de simples fichiers textes sans métadonnées. D’ailleurs les formats de fichiers de sous-titre sont encore souvent de bêtes fichiers textes avec une structure très basique (par exemple [les fichiers `.srt`](
https://en.wikipedia.org/wiki/SubRip#SubRip_file_format)), ce qui en fait justement des formats appréciés et encore très utilisés. Je pense qu’on est nombreux à encore ouvrir des fichiers textes et s’apercevoir parfois qu’ils sont cassés. On se dit alors que si son éditeur de texte avait de la reconnaissance de codage de caractères, cela aurait aidé !
C’est ainsi que malgré tous ces changements, un logiciel comme `uchardet` a encore tout son intérêt. Et d’ailleurs de l’autre côté, on voit qu’il y a maintenant plus d’alternatives viables qu’à l’époque.
Tout d’abord, Google a créé [CED](
https://github.com/google/compact_enc_det/) pour Chrome. Dans un [article de blog](
https://hsivonen.fi/chardetng/#ced), un développeur de Mozilla explique pourquoi, selon lui, ce n’était pas une bonne idée de partir sur ce projet, dans leur cas :
> License-wise the code is Open Source / Free Software, but it’s impractical to exercise the freedom to make modifications to its substance, which makes it close to an invariant section in *practice* (again, not as a matter of license). The code doesn’t come with the tools needed to regenerate its generated parts. And even if it did, the input to those tools would probably involve Google-specific data sources. There isn’t any design documentation (that I could find) beyond code comments. Adopting ced would have meant adopting a bunch of C++ code that we wouldn’t be able to meaningfully change.
Pour résumer, cette personne dit que *CED* n’est pas vraiment libre *en pratique* puisqu’on n’a pas les outils pour générer de nouveaux modèles, ni les données source. Donc on ne peut vraiment améliorer le code.
C’est en fait un commentaire très intéressant pour moi, car c’est justement l’état dans lequel Mozilla avait laissé son propre code dans ses dépôts, et donc celui dans lequel je l’ai trouvé en 2015 : de nombreux fichiers de code générés et à la logique opaque. C’est vraisemblablement la raison pour laquelle il y eut si peu de contributions avant moi : personne ne savait vraiment comment améliorer le cœur du logiciel et les rares contributions se concentraient sur l’interface ou l’outil en ligne de commande ; pas de nouveau codage pris en charge, ni aucune amélioration de l’efficacité avant 2015… J’ai passé énormément de temps à essayer de comprendre le code et les données générés (sans savoir comment il l’a été et avec quel jeu de données), à le démystifier et surtout à créer des [scripts](
https://gitlab.freedesktop.org/uchardet/uchardet/-/blob/master/script/BuildLangModel.py) de génération de modèles de langages à partir de données libres et publiques (contenu de Wikipédia). Mes scripts sont inclus dans le dépôt dès le début, et j’inclus même les logs de génération (ce qui permet de pouvoir étudier ces derniers ultérieurement si un modèle devait être problématique). C’est une forme très limitée d’ingénierie inversée, mais j’en suis plutôt fier, car c’est ce qui rend `uchardet` vraiment puissant (la simplicité de créer de nouveaux modèles). Les scripts de génération de modèles sont livrés et rien n’est opaque, par design. Néanmoins bien que j’ai démystifié une partie (les modèles pour les codages mono-octets), il reste certaines parties de code peu documentées (les codages multi-octets) qui parfois me laissent encore un peu pantois (je commence en fait à les remplacer progressivement plutôt que chercher absolument à les comprendre).
Quoi qu’il en soit, Firefox lui-même est revenu à faire de la [détection depuis Firefox 89](
https://support.mozilla.org/en-US/kb/text-encoding-no-longer-available-firefox-menu) (soit juin 2021). Cela n’est pas fait automatiquement mais en allant dans le menu `View > Repair Text Encoding`, ce qui fait que le lien vers leur propre page d’archive a encore un rendu cassé par défaut et il faut faire une action explicite dans un menu caché ([voir aussi ce post d’intention](
https://hsivonen.fi/no-encoding-menu/)) pour voir la page proprement.
Et c’est ainsi que Mozilla a décidé de ré-écrire un nouveau projet en Rust. Dans leur [article](
https://hsivonen.fi/chardetng/), ils citent `uchardet` (sans le [nommer autrement qu’un « fork non-Mozilla »](
https://hsivonen.fi/chardetng/#chardet) avec un lien vers la page d’`uchardet`) et le fait qu’il est bien plus complet maintenant qu’il ne l’était à l’époque, mais qu’il manque encore des fonctionnalités. Ils ont donc préféré ré-implémenter du début (une logique qui m’interpelle) et ce nouveau projet s’appelle [chardetng](
https://crates.io/crates/chardetng).
Notons qu’il existe une troisième alternative, nommée [ICU](
https://unicode-org.github.io/icu/userguide/conversion/detection.html). Je ne l’ai jamais testée (puisque je n’en ai plus l’intérêt, avec maintenant un système qui marche vraiment bien: `uchardet`! 😜), mais toujours d’après le développeur [Firefox](
https://hsivonen.fi/chardetng/#icu), ce détecteur serait bien moins précis que toutes les alternatives (`uchardet`, `chardetng` et `CED` donc) et aurait donc pour cette raison été rejeté par les équipes de Chrome et Mozilla.
# Comment fonctionne uchardet?
J’imagine que les projets cités utilisent des logiques similaires, même si je n’ai pas vérifié ces derniers en détail. Concentrons-nous sur `uchardet`.
## Algorithme naïf et premier concept: caractères interdits
Globalement l’idée de base des détecteurs de la vieille époque est qu’il suffit de vérifier si on tombe sur des octets interdits. Cela marche relativement bien pour certains codages multi-octets (tels que UTF-8) puisqu’il est assez facile de créer des données invalides dès qu’on écrit hors ASCII. Ces codages multi-octets sont d’ailleurs souvent assimilables à des machines à états (avec des états "*invalides*").
Néanmoins c’est bien moins vrai pour les jeux de caractères mono-octets. Énormément parmi ces derniers utilisent quasiment tout l’intervalle donné (voire son entièreté si on considère les caractères de contrôle comme admissibles, voir par exemple [ISO-8859-15](
https://fr.wikipedia.org/wiki/ISO/CEI_8859-15#Caract%C3%A8res_support%C3%A9s)). En outre, même lorsqu’ils sont incomplets, plusieurs codages occupent souvent les mêmes intervalles.
Ainsi [ISO-8859-1](
https://fr.wikipedia.org/wiki/ISO/CEI_8859-1#Caract%C3%A8res_support%C3%A9s) et ISO-8859-15 sont exactement sur les mêmes intervalles. Si on se limite à détecter les caractères interdits, il est ainsi impossible de différencier la validité en se contentant de tester le texte comme étant dans l’un de ces jeux de caractères: toute suite d’octets valide dans une version est valide dans l’autre également !
Voir par exemple les tableaux des 2 codages où on voit que les mêmes intervalles d’octets sont utilisés:
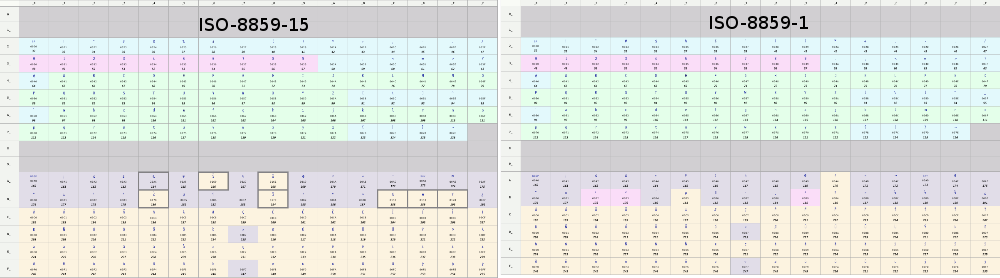
C’est pourquoi un algorithme qui ne cherche qu’à vérifier la validité de la séquence ne peut dire que "*Luke, je suis ton pÚre!*" ne convient pas puisque c’est une séquence valide en ISO-8859-15 (mais en tentant de lire un texte UTF-8).
Malheureusement divers logiciels libres utilisaient (et utilisent encore) une telle logique naïve : boucler en passant le texte dans `iconv`, testant alternativement des jeux de caractères dans une liste. Puis on s’arrête au premier jeu qui ne retourne pas en erreur (ce n’est pas un exemple au hasard, j’ai vu cet algorithme dans certains gros logiciels). Avec une telle logique, vous pouvez être certain de ne quasiment jamais avoir le bon résultat pour la plupart des jeux mono-octets. 😱
## Statistiques des caractères utilisés dans un langage
C’est là où le second concept apparaît: « *même si les mêmes emplacements sont utilisés dans 2 jeux de caractères, tous les emplacements ne sont possiblement pas tous utilisés dans tous les langages.* »
Dans notre exemple fictif, le caractère '€' se trouve à l’emplacement `0xA4` dans ISO-8859-15, et '¤' (« symbole monétaire générique ») dans ISO-8859-1. On peut voir comment cela met ISO-8859-15 en avant pour un texte d’une langue européenne. De même, les caractères `0xBC` et `0xBD` représentent “Œ” et “œ” respectivement en ISO-8859-15, et '¼' et '½' en ISO-8859-1. Bien qu’on puisse avoir des quarts et demis, on sait que ces derniers sont peu utilisés, alors que dans un texte en français, les e-dans-l’o sont des caractères utilisés.
Par contre, `ISO-8859-15` peut aussi être utilisé dans divers autres langages, par exemple l’italien qui n’utilise pas le “œ”. Ainsi trouver ce caractère pourrait augmenter la confiance qu’on soit en train de lire un texte français et diminuer celle qu’on soit en présence d’un texte italien.
Et si on obtenait des statistiques de caractères qui apparaissent par langage ?
On découvre ainsi que [certains caractères sont extrêmement courants](
https://fr.wikipedia.org/wiki/Fr%C3%A9quence_d%27apparition_des_lettres#Dans_d'autres_langues), quand d’autres sont très rares voire inexistants selon le langage. Les statistiques se révèlent suffisamment différentes même entre langues sœurs.
## Séquences de caractères
Néanmoins ces statistiques de caractère ne sont toujours pas assez.
Le troisième concept est donc d’aller regarder non plus par caractère, mais par séquence de caractère. On se rend compte ainsi que si on a un “œuf” ou un "½uf », les 2 étant des résultats valides pour un même ensemble de 3 octets selon qu’on les décode avec la table `ISO-8859-15` ou `ISO-8859-1`, statistiquement, “œ” suivi de “u” est une séquence relativement courante en français (“œuf”, “sœur”, “bœuf”…) mais ce n’est pas le cas de '½' suivi de “u”. Si on avait encore le moindre doute qui pouvait subsister, il n’est probablement plus.
Ce dernier concept est donc de générer des statistiques de suites de 2 caractères. En fait, on se limite à 2 lettres (et non “caractère”, terme plus générique qui inclut aussi des symboles, des chiffres, etc.), ce qui fait que mon exemple n’est pas aussi significatif que voulu — '½' n’étant pas une lettre — mais vous voyez l’idée!
Ce concept sur les séquences de lettres donne des résultats extrêmement pertinents pour qualifier le langage d’un texte.
## Conclusion : un mix de tout ça!
Le principe de `uchardet` et peut-être de tous les autres systèmes de détection modernes est donc d’utiliser ces 3 concepts. La détection naïve est toujours d’actualité, mais elle ne sert que de raccourci pour les cas les plus simples.
À partir de statistiques par langues (générées et compilées dans des modèles), on cherchera donc à identifier le langage le plus probable. En fait, `uchardet` est autant un détecteur de langage qu’il est un détecteur de codage de caractère. On cherche à calculer les probabilités qu’une suite d’octets soit un texte d’un langage donné avec un codage donné. On assigne ainsi un score “confiance” pour chaque couple `(langage, codage)`. Et on retourne simplement le jeu de caractère du couple avec le plus haut score.
Ces statistiques sont compilées à partir de texte Wikipédia, grâce à mon script qui génère des tables en fichiers source qui seront compilés. C’est pourquoi la détection est au final extrêmement rapide tout en étant précise.
## Conclusion 2 : `uchardet` ne fait pas de magie mais n’en est pas moins impressionnant !
J’ai de temps en temps des rapports de bugs avec des gens qui se plaignent que des textes de test ne sont pas convenablement détectés. Parfois il s’agit soit de tests sur quelques caractères à peine, soit de caractères aléatoires.
Vous l’aurez compris, dans le premier cas, `uchardet` pourrait fonctionner mais étant un outil statistique, il est évident que plus il y a de texte, plus on peut avoir confiance en la réponse. `uchardet` ne fait notamment pas de recherche dictionnaire (ce qui aurait un tout autre coût temporel et rendrait l’outil très lent) ni d’étude grammaticale. Les chances de trouver le bon jeu de caractère si tout ce que vous avez est un unique mot de quelques caractères est forcément plus sujet à erreur.
Dans le second cas, c’est carrément contraire à la logique d’`uchardet`. On a eu des cas où des gens testaient une seule lettre dans divers jeux de caractères et n’étaient pas content qu’`uchardet` ne trouvait pas le bon jeu. Comme expliqué plus haut, d’autant plus si le caractère est mono-octet, sa version codée est probablement valide dans des dizaines de jeux de caractères, voire tous. Dans le cas d’une séquence aléatoire de caractères, cela ne fera qu’embrouiller les modèles statistiques de la librairie qui cherchera à assigner un score selon des fréquences de séquences qui ne correspondent en fait à aucune langue.
Il y a aussi le fait de mélanger les langues, ce qui n’est pas un problème en soi s’il y a suffisamment de texte (puisqu’on travaille statistiquement, même s’il y a une citation dans une langue étrangère, on peut supposer que le gros du texte est dans la langue à chercher, et c’est suffisant pour faire pencher la balance). Une variante de cela est les balises de formatage de fichier, lesquelles contiennent souvent de l’anglais. J’en parlais plus haut dans mon exemple avec un fichier HTML. Il est conseillé de nettoyer les balises et ne garder que le contenu pour une détection plus fiable. Bien sûr, ces balises ne feront que baisser un peu les scores et si le vrai contenu est suffisamment conséquent, cela pose peu de problème.
Enfin `uchardet` ne détecte donc pas des codages, mais bien des couples de `(langage, codage)`. La liste précise de la version 0.0.8 est [disponible sur le site](
https://www.freedesktop.org/wiki/Software/uchardet/#supportedlanguagesencodings). C’est ainsi que nous pouvons détecter un texte par exemple en `ISO-8859-15` écrit en danois, finnois, français, irlandais, italien, norvégien, portugais, espagnol et suédois. S’il advenait qu’on cherche à tester un texte utilisant ce codage dans un autre langage, il y a de fortes chances que l’outil fonctionnerait moins bien : il pourrait quand même donner le bon codage, mais ce serait par chance (probablement par similarité statistique avec une autre langue, mais sûrement avec un score de concordance médiocre). Une façon de contribuer à `uchardet` est donc de créer des [fichiers de langue](
https://gitlab.freedesktop.org/uchardet/uchardet/-/tree/master/script/langs), des [fichiers de jeux de caractère](
https://gitlab.freedesktop.org/uchardet/uchardet/-/tree/master/script/charsets) puis lancer le script de génération de modèle comme expliqué dans ce petit [README](
https://gitlab.freedesktop.org/uchardet/uchardet/-/blob/master/script/README) pour développeurs. Plus nous prendrons en charge de couples de langue et codage, plus l’outil sera utile.
# Futur : API de détection de langage
J’ai commencé (depuis 2020, à intervalle irrégulier) de travailler à étendre l’usage d’`uchardet` pour faire de la détection de langage. Comme je l’ai expliqué, c’est en fait déjà le cas en interne, sauf que la langue détectée ne ressortait pas dans les résultats de l’outil. Historiquement l’outil ne sert que pour détecter le codage d’un fichier.
J’ai toujours trouvé cela dommage et c’est donc la direction que prend le projet puisque je viens de fusionner ma branche de travail de long terme sur le dépôt principal, pour la future version `uchardet 0.1.0`.
`uchardet` 0.0.8 est donc probablement la dernière version qui ne retourne que le codage du texte. La version suivante permettra aussi d’en connaître le langage.
Cette future version retournera désormais une liste de candidats et les scores de confiance de chacun, permettant par exemple à un logiciel de ne pas juste se fier au premier résultat. Si 2 résultats ont un score très proche, un logiciel intéractif pourrait décider d’afficher une boîte de dialogue proposant les 2 codages avec prévisualisation, ou en demandant la langue présumée du texte.
J’ai aussi commencé à ajouter des systèmes de poids (pas comme les vieilles bibliothèques de détection bien sûr, au contraire pour permettre d’implémenter des systèmes plus intelligents), mais j’en parlerai dans une future dépêche pour ne pas trop *spoiler*.
J’ai pas mal de développements en cours, non seulement sur l’API mais aussi sur la précision de détection qui a déjà fait un énorme bond entre la version 0.0.8 à peine sortie et le code en développement.
De manière générale, même si les 3 concepts explicités plus haut sont toujours globalement à la base de la détection, je les ai fait évoluer, avec de nouveaux concepts ou sous-concepts et j’ai revu les calculs. C’était en réalité déjà le cas dans les versions 0.0.\*, mais ça le sera encore davantage avec les versions 0.1.\* à venir.
Certaines parties du calcul originel des scores de confiance n’avaient en fait pas beaucoup de sens statistique et *marchaient* parfois un peu par “chance” (disons plutôt : sûrement des tests arbitraires des développeurs d’origine qui avaient des effets de bords valides statistiquement, mais avec une logique un peu bancale). Je revois donc ces calculs en permanence en me basant sur mes expérimentations statistiques. Ça me prend pas mal de temps, car il commence à y avoir beaucoup de modèles à régénérer à chaque changement dans la logique des modèles (plus d’une centaine de modèles de séquences pour plusieurs dizaines de modèles de langues). Les résultats sont en tous cas extrêmement prometteurs.
L’une des conséquences, notamment, est que les versions suivantes devraient prendre en charge beaucoup plus de couples de `(langage, codage)`, et avec plus de fiabilité.
J’ai encore du travail sur cette branche, mais elle avance bien. J’espère pouvoir sortir `uchardet` 0.1.0 en 2023.
# Conclusion et financement
Cette bibliothèque est un petit projet annexe (à mon plus gros projet, [GIMP](
https://linuxfr.org/news/gimp-fete-ses-27-ans-avec-la-version-de-developpement-2-99-14)) qui m’a toujours beaucoup plu puisque j’aime énormément le traitement des langues (je maintiens d’ailleurs quelques autres projets autour de ce sujet).
Je le développe par à-coup, notamment lorsque j’ai besoin de faire une petite pause dans mon développement sur GIMP (la charge est lourde), ce qui fut le cas ce mois de décembre, où j’ai fait un mini *burn-out* après la sortie de GIMP 2.99.14 et avais besoin de décompresser en codant autre chose (ce qui ne m’a pas empêché de faire quelques *commits* sur GIMP, des revues de code, de gérer les activités au jour le jour et de répondre à des rapports de bug 😅 ; peut-être devrais-je revoir ma définition de pause…).
En tous les cas, j’espère que vous appréciez ce projet qui est déjà pas mal utilisé.
Au passage, je ne peux que rappeler que si vous appréciez mon code, vous pouvez me financer à travers le [projet “ZeMarmot”](
https://film.zemarmot.net/) (sur [Liberapay](
https://liberapay.com/ZeMarmot/) ou [Patreon](
https://www.patreon.com/zemarmot) notamment, ou même par donations en virement direct en contactant l’association [LILA](
https://libreart.info/fr/donate)).
Certes uchardet n’est pas un produit direct du projet “ZeMarmot” mais c’est le moyen le plus sûr de me payer officiellement pour développer du code libre, et par conséquent tout autre projet libre que je fais en est aussi une conséquence indirecte (y compris `uchardet`). Donc si vous appréciez `uchardet` et l’utilisez dans votre code (ou si vous l’utilisez indirectement parce que vous regardez des films avec `mpv` ou un lecteur basé sur `QtAV`), financez “ZeMarmot” pour assurer la pérennité de cette librairie, s’il vous plaît! 🤗
Je vous souhaite de belles fêtes de fin d’année à tous, et ce quelle que soit la langue:
```sh
$ echo « Joyeux Noël et bonnes fêtes de fin d’année! » | uchardet -V
UTF-8 / fr (0.793221)
UTF-8 / vi (0.706612)
UTF-8 / sl (0.665267)
UTF-8 / sv (0.661734)
UTF-8 / es (0.622741)
[…]
$ echo "메리 크리스마스! » | uchardet -V
UTF-8 / ko (0.990000)
IBM866 / ru (0.396848)
```
*Note: l’option `-V` donnant les scores de confiance et les candidats de couples de codage/langue ne se trouve pour l’instant que dans le code en développement, qui a détecté le français et coréen ici. Inutile de le tester sur uchardet 0.0.8. C’est un petit teaser sur le futur d'`uchardet`!* 😜
🎅🎉🥂
{kind=link}
{kind=link}