URL:
https://linuxfr.org/news/vtk-la-visualisation-scientifique-et-au-dela
Title: VTK : la visualisation scientifique et au delà !
Authors: mzf
Ysabeau, Pierre Jarillon et palm123
Date: 2021-02-03T21:45:22+01:00
License: CC By-SA
Tags: vtk, visualisation, scientifique, kitware et paraview
Score: 5
VTK est une bibliothèque libre incontournable de la visualisation scientifique, pourtant peu citée sur LinuxFr. Rattrapons le retard !

[[VTK]] est en quelque sorte le couteau suisse de la visualisation scientifique. La suite de cet article vous donnera un aperçu de ses domaines d’utilisation en s’appuyant sur de nombreux exemples abondamment illustrés.
----
[Site officiel](
https://vtk.org/)
[Exemples](
https://kitware.github.io/vtk-examples/site/)
[Code source](
https://gitlab.kitware.com/vtk/vtk)
----
# Visualisation Scientifique
Le domaine d’application premier de [[VTK]] est la visualisation scientifique. C’est une discipline très large qui couvre les représentations possibles de données issues du domaine scientifique dans le but de les rendre interprétables par des humains :
* résultats de simulations : météo, astrophysique, fluides…

* mesures venant de capteurs : imagerie médicale, inspection des sols…

* données créées ex-nihilo : équation mathématique, données historiques ou géographiques…

Une particularité de cette visualisation est de rendre les données compréhensibles pour l’utilisateur dans un but d’analyse. Être capable de représenter ces données d’une façon simple est en général assez complexe ! Elles doivent être transformées, simplifiées, projetées sur des primitives géométriques (points, lignes, surfaces, etc.), colorées, combinées, superposées, etc.
De plus ces données sont souvent brutes et peuvent être de taille considérable, de l’ordre du gigaoctet ou du téraoctet, et nécessitent en général plusieurs traitements lourds pour en extraire des informations pertinentes pour l’observateur. Pour des questions de performance ces transformations doivent pouvoir s’exécuter en parallèle en utilisant un maximum de ressources disponibles : CPU, GPU, grappe de serveurs, etc.
En 1993, seuls quelques logiciels propriétaires étaient capables de répondre à toutes ces contraintes. Comme nous allons le voir par la suite, la publication de VTK sous une licence libre, donc gratuite, lui a permis de devenir rapidement une solution de référence pour des utilisateurs assez divers.
# Historique
VTK est l’acronyme de *Visualization Toolkit*, soit littéralement *boîte à outils de visualisation* en français. Cette bibliothèque est à l’origine un logiciel accompagnant le livre [The Visualization Toolkit: An Object-Oriented Approach to 3D Graphics](
https://vtk.org/documentation/#textbook) écrit par trois chercheurs, Will Schroeder, Ken Martin et Bill Lorensen, travaillant à l’époque, en 1993, chez General Electric R&D. Leur propos était de collaborer avec d’autres chercheurs et de développer des outils communs pour créer des applications avancées de visualisation de données. Leur employeur les autorisa à publier ce livre écrit sur leur temps libre ainsi que le code source sous une licence libre.

Au début utilisé principalement en interne par General Electric pour le domaine médical, la bibliothèque rencontra rapidement du succès dans l’univers de la recherche scientifique. Ceci amena deux des auteurs du livre à créer la société [Kitware](
https://www.kitware.com) en 1998 pour répondre aux demandes des utilisateurs et contributeurs que ce soit des laboratoires de recherche ou des entreprises.
Au cours de son développement, les applications utilisant VTK se sont diversifiées comme le traitement d’image, la vision par ordinateur ou l’analyse de données.
Le livre en est aujourd’hui à sa quatrième édition, et VTK est en version 9.0 avec une version majeure tous les 2 à 3 ans. Cette dernière version amène de [nombreuses nouveautés](
https://discourse.vtk.org/t/vtk-9-0-0/3205), dont les plus visibles sont :
* rendu physique réaliste, comparaison entre un matériau non métallique à gauche et un autre métallique à droite

* l’occlusion ambiante, qui améliore la perception de profondeur

* éléments de maillage de type Bézier
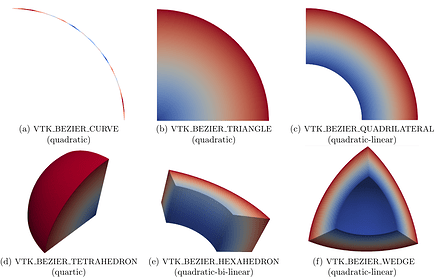
Ces nouvelles fonctionnalités permettent des rendus réalistes modernes comme vous pouvez le constater parcourant la [chaîne vidéo de Kitware](
https://vimeo.com/kitware) :
[](
https://vimeo.com/473470991)
[](
https://vimeo.com/473470865)
[](
https://vimeo.com/473470813)
# Kitware
Petite parenthèse sur Kitware, cette entreprise assez particulière qui développe VTK.

Vous connaissez peut-être déjà Kitware pour ses nombreux autres logiciels libres : [CMake](
https://cmake.org/), [CDash](
https://www.cdash.org/), [ITK](
https://itk.org), [Paraview](
https://www.paraview.org/)… qui naviguent tous autour de l’univers de la visualisation et du développement logiciel de grande ampleur.
Kitware est une société américaine, avec une succursale à Lyon en France, d’environ 150 personnes qui développe les outils sus-cité et en propose la maintenance ainsi que des formations et des développements spécifiques. Fait rare, son *CEO*, [Lisa Avila](
https://www.kitware.com/lisa-avila), est une femme et [l’équipe dirigeante](
https://www.kitware.com/leadership-management/) est aussi partiellement féminine. Autre point positif, l’entreprise est détenue à 100% par ses employés [depuis peu](
https://blog.kitware.com/kitware-becomes-100-percent-employee-owned/). D’ailleurs dans un [article récent](
https://www.bizjournals.com/albany/news/2020/10/13/kitware-growing-software-development-talent.html) on apprend que l’entreprise a du mal à recruter. Les profils recherchés, techniquement pointus, amènent Kitware à rentrer en concurrence avec les géants américains de l’informatique comme Google ou Amazon.
Comme beaucoup d’entreprises qui développent des logiciels libres, le modèle économique de Kitware semble être un mélange entre du développement spécifique de niche autour de leurs outils, et de la formation couplé à de la maintenance pour utilisateurs avancés. De plus, en parcourant leur blog on peut constater que Kitware participe à beaucoup de projets de recherche américains et européens. Comme l’explique Lisa Avila dans cet [article](
https://www.saratoga.com/saratogabusinessjournal/2019/10/lisa-avila-moves-from-ge-research-unit-to-help-form-kitware-inc-in-clifton-park/), chaque client a des besoins très spécifiques ce qui demande beaucoup d’accompagnement commercial avec un suivi financier efficace pour garantir la pérennité des projets de recherche.
# Principes de fonctionnement de VTK
Passons à la technique !
Le cœur de VTK est développé en C++, mais il existe de nombreux portages et il est ainsi possible de s’en servir en Tcl, Python, Jupyter (via [Paraview Jupyter Kernel](
https://blog.kitware.com/paraview-jupyter-notebook/)), Visual Basic, C# (via [ActiViz](
https://www.kitware.eu/activiz/)), Java, Javascript (via [vtk.js](
https://blog.kitware.com/vtk-js-the-visualization-toolkit-on-the-web/)), Unity… et j’en oublie sûrement !
VTK utilise la [programmation orienté objet](
https://fr.wikipedia.org/wiki/Programmation_orient%C3%A9e_objet), c’est-à-dire que chaque concept ou action est représentée par un *objet*. Un objet regroupe les données spécifiques à sa tâche et des actions qui peuvent s’appliquer sur ces données, tout en interdisant le reste du programme d’y accéder. C’est le principe de [l’encapsulation](
https://fr.wikipedia.org/wiki/Encapsulation_(programmation)), très populaire dans les langages C++, Java, C#…
À noter que VTK défini aussi son [propre format de stockage de donnée](
https://kitware.github.io/vtk-examples/site/VTKFileFormats/) dont les fichiers ont en général l’extension *.vtk* ou l’une de ses variantes (*vtu*, *vti*, *vtp*…). Avec le temps, le format a évolué et on trouve aujourd’hui à la fois l’ancienne version texte brut, aujourd’hui obsolète, ou la version plus moderne en XML. Cette dernière peut contenir des données binaires en plus des balises XML, ce qui permet d’accélérer le chargement, ainsi que la possibilité de lecture et écriture en parallèle de plusieurs sections d’un même fichier.
## Pipeline
VTK fonctionne en *pipeline* configurable. Cela signifie que les données vont subir plusieurs transformations ou actions jusqu’à leurs multiples représentations finales. En simplifiant, on peut dire VTK défini deux familles d’objets : les objets de données et les objets de traitement sur celles-ci, appelés *process* en anglais.
Il existe ainsi trois type de processus :
* les sources qui ne prennent rien en entrée mais qui produisent une sortie

* les filtres qui acceptent des données en entrée et en produisent en sortie

* les puits (*sink* en anglais) qui ont besoin de données en entrée mais ne produisent rien en sortie. Même s’ils n’ont pas de flux de sortie au sens de la *pipeline*, cela n’empêche pas d’effectuer des actions d’entrée/sortie système comme de l’affichage ou l’écriture dans un fichier.

Notez que sur les illustrations ci-dessus, une seule flèche est représentée par simplification alors qu’un processus peut accepter et générer plusieurs données.
Donc en combinant différents processus on obtient une succession d’étapes qui permettent à partir d’une source de donnée brute d’arriver à de multiples représentations graphiques.
L’utilisation d’une *pipeline* permet aussi une mise jour automatique du rendu quand un paramètre change. Si la source change, tout doit être recalculé, mais si seul un paramètre d’un filtre change, seules les étapes en aval seront mises à jour.
Il existe plusieurs centaines de filtres disponibles dans VTK, couvrant de nombreux besoins. Nous allons en voir quelques-uns dans les exemples suivants.
# Quelques exemples
## Jouons avec une quadrique
Exemple concret adapté du VTK TextBook, imaginons qu’on souhaite explorer la [quadrique](
https://fr.wikipedia.org/wiki/Quadrique) suivante :
$$F(x,y,z) = x^2 + 2*y^2 + 4*z^2 + 5*x*y + y*z$$
Notre fonction associe une valeur à tout point de l’espace à 3 dimensions. Pour la représenter nous allons générer et afficher des surfaces de niveau et des lignes de niveau, ce qui revient mathématiquement à dessiner l’ensemble des points $(x,y,z)$ pour lesquels $F(x,y,z) = K$ avec $K$ une constante.
Construisons notre *pipeline* qui doit contenir une source, des filtres et pour finir un système de rendu.
Première étape : la source, qui est de type *vtkQuadric*, un objet bien pratique qui représente une quadrique.
On échantillonne cette source avec un *vtkSampleFunction* pour obtenir un ensemble discret de points, que l’on va ensuite passer dans un filtre de contour *vtkContourFilter* qui extrait des surfaces dont les points ont la même valeur. À cette étape les surfaces ne sont que des objets mathématiques sans réalité physique. Il faut donc utiliser un *vtkPolyDataMapper* pour les associer à des primitives graphiques dans le but de leur affichage. Dans notre cas ces primitives sont des triangles colorés en fonction de la valeur des points des différentes surfaces.
Dernière étape, il faut placer nos primitives dans la scène 3D via un acteur *vtkActor* lié à la fenêtre graphique, elle-même combinaison de plusieurs objets : *vtkRenderer*, *vtkRenderWindow*, *vtkRenderWindowInteractor*… Le concept d’acteur permet d’ajouter des transformations spatiales (translation/rotation/homothétie/etc.) à des primitives indépendamment de l’espace de rendu.
Si on représente graphiquement notre *pipeline*, elle ressemble à ça :

Et le résultat :

On observe ainsi les différentes surfaces de niveau colorées.
Complexifions maintenant en superposant d’autres visualisations de cette même source.
Pour extraire et afficher des lignes de niveau sur plusieurs plans, nous allons utiliser un extracteur de volume *vtkExtractVOI* qui permet de travailler sur un sous-ensemble d’échantillons. Dans notre cas ces échantillons seront situés sur un plan. La suite est similaire à la visualisation précédente en utilisant un filtre de contour qui va cette fois-ci extraire des segments au lieu des surfaces. Les primitives graphiques vont ainsi être des lignes et on utilisera aussi un acteur *vtkActor* pour placer le dessin dans la même fenêtre de rendu.
Dans la représentation graphique de la *pipeline*, on trouve ainsi deux branches qui partent de la même source et finissent dans la même scène de rendu mais en passant par des filtres différents : l’une pour les surfaces de niveau, l’autre pour les lignes de contours.

résultat :

Mais on n’y voit rien ! C’est à cause des représentations superposées. On peut alors soit jouer sur la transparence pour rendre les lignes visibles, soit les déplacer dans le rendu final grâce à l’objet « acteur » associé :

Et en rajoutant une boîte englobante pour mieux se situer dans l’espace :

## Rendu volumique
Exemple un peu plus avancé, nous allons travailler sur une source volumique qui contient des informations pour chaque [voxel](
https://fr.wikipedia.org/wiki/Voxel) d’un espace 3D. C’est le cas typique de données venant d'[imagerie par résonance magnétique (IRM)](
https://fr.wikipedia.org/wiki/Imagerie_par_r%C3%A9sonance_magn%C3%A9tique). Pour se représenter les choses, on peut utiliser l’analogie d’un grand Rubik's cube avec une valeur associée à chaque case.

Voici la version *Rubik's cube* de nos données :

Difficile de comprendre ce qu’il y a à l’intérieur !
Si on reprend les méthodes décrites dans l’exemple précédent, on peut imaginer plusieurs façons de visualiser ces données :
* projeter la valeur de chaque voxel sur un point de l’espace 3D, comme l’image *rubik's cube* ci-dessus
* afficher des lignes de contours ou des surfaces de contours


Mais comme on le voit dans les captures d’écran ci-dessus, les surfaces comportent des trous car les différentes parties (peau, crâne, etc.) sont représentés par une plage de valeur et non plus par une seule valeur. On peut évidemment superposer plusieurs surfaces, mais il est toujours difficile de percevoir l’intérieur du modèle, ce qui est pourtant le but recherché en imagerie médicale (recherche de tumeur par exemple) :

La solution ? Utiliser le lancer de rayon (*raycasting*) !
L’idée est de faire partir un rayon pour chaque pixel de l’image de rendu. Ce rayon va traverser notre volume voxélisé et recueillir des informations à chaque cube traversé. Il suffira ensuite de se servir de ces informations pour définir la couleur du pixel de l’image.
Il existe de nombreuses façons de faire ce dernier calcul en fonction de ce que l’utilisateur souhaite afficher. On peut citer :
* utiliser la moyenne des valeurs des cubes traversés ;
* utiliser la valeur maximale des cubes traversés, abrégé MIP pour *[maximum intensity projection](
https://en.wikipedia.org/wiki/Maximum_intensity_projection)* ;
* utiliser la valeur minimale des cubes traversés, abrégé MinIP pour *[minimum intensity projection](
https://en.wikipedia.org/wiki/Minimum_intensity_projection)* ;
* somme des valeurs traversées ;
* intégrale des valeurs traversées ;
* etc.
Dans cet exemple nous allons utiliser la valeur maximale grâce au filtre *vtkFixedPointVolumeRayCastMapper*. Voici notre pipeline :

Elle commence par *reader* qui ne prend rien en entrée mais agit sur le système en lisant le fichier, puis on utilise un *VolumeRayCastMapper* qui va se charger de faire le lancer de rayon et le calcul *MIP*. On le passe ensuite à l’objet *vtkVolume* qui est le pendant volumique du *vtkActor* utilisé pour les primitives géométriques.
Le résultat :

Ça y est on commence à voir l’intérieur et l’extérieur. La couleur d’un pixel est donc la valeur maximale du matériau traversé, en gros le matériau le plus dense (les os et les dents dans notre cas). Mais il est encore difficile de situer chacun des éléments dans l’espace, ce qui est l’inconvénient majeur de la méthode *MIP*. On peut contourner ce problème en créant une animation :

Il est ensuite possible de colorer les différents pixels grâce à une fonction qui va associer chaque valeur à une couleur, appelée *fonction de transfert*. Si on connaît la plage de valeur de chaque élément à faire ressortir, on peut lui associer des couleurs similaires. Ici les dents en rouge, les os en jaune et la peau en bleu :

## Autres types de rendu
Ces exemples simples ont permis de découvrir toute la souplesse et la puissance de l’architecture en *pipeline* de VTK. Il existe de nombreux autres filtres qui répondent aux besoins de la visualisation de données scientifiques. Citons les grandes catégories :
* la coloration, c’est-à-dire associer une plage de valeur à un ensemble de couleurs :

* création de contours (lignes, surface…)

* affichage de symboles (*glyphs*)

* affichage de lignes de courant (*streamlines*)

* découpage de volume

* déformation de maillages

* travail sur des images

* rendu volumique

* rendu géographique
* affichage de graphes
* analyse de données (*Big Data*)
* …
Et, s’il vous manque des outils, le code ouvert et l’architecture modulaire de VTK permettent de les développer, soit vous-même, soit via un prestataire tel que [Kitware](
https://www.kitware.eu/what-we-offer/). Vous pouvez aussi en discuter sur le [forum de VTK](
https://discourse.vtk.org/) ou encore participer directement au développement (rapport de bug, discussion, proposition de nouvelle fonctionnalité…) sur l'[instance gitlab](
https://gitlab.kitware.com/vtk/vtk) dédiée.
# Conclusion
VTK est donc une boîte à outils très puissante dédiée à la visualisation de données. Cette présentation n’a fait qu’effleurer les fonctionnalités de base pour illustrer l’utilisation de la *pipeline*, et je vous encourage à aller consulter les [exemples](
https://kitware.github.io/vtk-examples/site/Cxx/) pour un panorama plus complet.
Pour finir, si vous ne développez pas des applications de visualisation scientifique, il se peut qu’associer les filtres à la main via un langage de programmation vous paraisse assez laborieux. C’est pour cela que Kitware a développé une application qui s’appuie sur VTK et permet de manipuler très facilement la *pipeline* : [Paraview](
https://www.paraview.org/).
Mais ce sera pour une prochaine dépêche !
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}